This article was originally written for the 'Medium' blog by Emma Mani, a Data Scientist for FT. It aims to walk you through the process our Data Science team undertook to decide on a model to upgrade the existing article vectorisation model.
Article Vectorisation Reloaded

What is Article Vectorisation?
Simply put, vectorisation of text data is a way to apply an algorithm to an input of text and produce an output of a series of numbers i.e. a vector. Vectors, also known as embeddings, therefore encode the interpretation of documents or words in a way that can be easily understood by machines. Vectors are commonly chosen over using raw text inputs due to their capability to be used harmoniously across different Natural Language Processing (NLP) applications, for example document classification, text similarity and information retrieval.
Setting the Scene: The Current Model
The existing, legacy FT article vectorisation model produces vectors with a dimension of 30, calculated using the Doc2Vec Gensim implementation. Subsequently, this legacy vectoriser is deployed to an Amazon Web Services Lambda where our colleagues in the Data Platform team monitor the operational aspect of the model. This model was integrated into a variety of FT Data Science Models as listed below:
- Article Clustering
A model to take newly published articles to a cluster comprising articles of similar content (see the FT Product and Tech Article). - Breadth of Readership
A metric which determines how broad a user’s reading is. For example, narrow breadth of reading would represent a subscriber who reads articles from one particular topic or may re-read a small number of articles. - Article Recommendations
A recommendation model which combines elements of the Article Clustering and Breadth of Reading to suggest FT content from a ‘nearby cluster’ based on what users usually read. - Trending Topics
A model which highlights FT content which has attracted unusual reader traffic in the last 90 days. (read the FT Product & Tech Medium Article for more information).
So why upgrade?
The above model is certainly functional and currently well implemented into our Data Science modelling infrastructure. However at the FT, other teams across the wider business were also looking to incorporate article vectors into various projects. For example our colleagues in the Content Analytics team required article vectors to feed into a classification model for Environmental / Social / Governance based articles. In view of this, a request to upgrade our current vectoriser was put forward to unite the process of identifying articles in a numerical dimensional vector space that would be robust and versatile to support wider use cases, teams and project types.
Steps to upgrade
- Research currently available vectorisation methods
- Decide on a suitable sample input dataset
- Prepare the candidate models for evaluation
- Record and evaluate the performance of the candidate models
- Decide on the winning vectorisation method
1. Research Stage
At the start of the project, currently available vectorisation methods were examined against the below criteria to be considered for the candidate shortlist:
- Evidence of their capability to be utilised for similarity search, classification and clustering/topic modelling
- Strong code-based documentation for implementation best practice
- Strong qualitative documentation explaining contextual model information
- Size of the models (storage and run times)
- Input text length limits for the model
- Output size of the vectors
Note that while this section details the different methods that were evaluated, the focus will be to discuss each method and its relevance to the FT project rather than theory about the specific method.
The methods explored and considered included:
- TF-IDF
TF-IDF is a method used to evaluate the importance or weighting of words/tokens to a set of documents within a corpus. The approach comprises two key calculations, the Term Frequency (TF) and the Inverse Document Frequency (more information on the calculation of TF-IDF with the scikit-learn framework can be found in the scikit-learn documentation). In terms of relevance to the FT article vectorisation project, TF-IDF can utilise the full article (including the text, summary, and title). The method is fast and easy to interpret. These factors ensured TF-IDF would feature in the shortlist. However it was important to note that the resulting matrix of TF-IDF vectors would be large and sparse, making it difficult to be applied at scale.
- Pooled Word Embeddings
Word embeddings are vector representations of words that capture their semantic and syntactic meaning. Hence a pooled word embedding builds on this methodology to generate a dense representation of a document or sentence by summarising its constituent words. An example of how pooled word embeddings can be implemented in Python using the flairNLP library can be found in the flairNLP repo. There are a variety of pooled word embedding methods: for example, taking the average of word embeddings. Averaging word vectors over a document provides for a very fast baseline that is also shown to perform on par or better than vanilla BERT embeddings for a number of tasks, as documented in a paper by the author of sentence transformers Nils Reimer (see paper). Subsequently, within the FT article vectorisation project a mean embedding on the GloVe word embedding was chosen to represent the pooled word embeddings team. This model, similarly to TF-IDF, can consider the full article (article text body, summary and title) as a text input.
- Variations of Doc2Vec (i.e. changing the parameters to different variations)
Doc2Vec is an extension of the Word2Vec algorithm in that a feature vector is created for every document in the corpus in addition to every word in the corpus (more information on Doc2Vec can be found in the Gensim documentation). The current FT Doc2Vec vectorisation model has demonstrated that output vectors from Doc2Vec can be integrated into a variety of FT Data Science models and this put forward the case to keep Doc2Vec in the shortlist of candidates. Also supporting this case is the factor that together with TF-IDF and pooled word embedding methods, Doc2Vec has no text input length limit and can consider the full article (article text body, summary and title).
- Sentence Transformers
Sentence Transformers are a series of Natural Language Processing models which focus on sentence, text and image embeddings. These models are designed based on the Transformers & PyTorch frameworks. More information about Sentence Transformers architecture can be found in this paper written by Nils Reimers and Iryna Gurevych. Sentence Transformers were selected as a candidate for the FT article vectorisation project as research from their documentation and academic studies identifies that vanilla Transformers (specifically Encoders) like BERT are not capable of producing document level embeddings, only token-level embeddings. These token-level embeddings would need to be pooled or the individual token embeddings (e.g. the CLS BERT token) would need to be used as representation of the whole document; however in this paper this adaptation mostly results in badly performing document embeddings. Hence this issue is overcome by the siamese transformer network utilised by Sentence Transformers. While these models have been identified as performing well in tasks utilising the cosine similarity such as semantic search or clustering, Sentence Transformers have some more rigid parameters compared to other candidates in the shortlist. In particular each sentence transformer has a default text input length parameter e.g. 384 tokens with the ability to increase this to 512 tokens maximum. Any text inputs longer than 512 tokens therefore would need to be truncated at the point of 512 tokens.
2. Sample Dataset
The next phase of the project was to create a sample dataset of FT articles that could be utilised to test the candidate models. Often within natural language processing projects, the quality and length of text data can be an issue, with the common use of slang terms, emoji annotations and hyperlink litter. These can diminish the strength of a numerical vector representation of text. At the FT, however, from a Natural Language Perspective, we are really lucky! Our articles, written by the Editorial team are written consistently, well-structured, correctly punctuated and topped off with a descriptive title and summary.
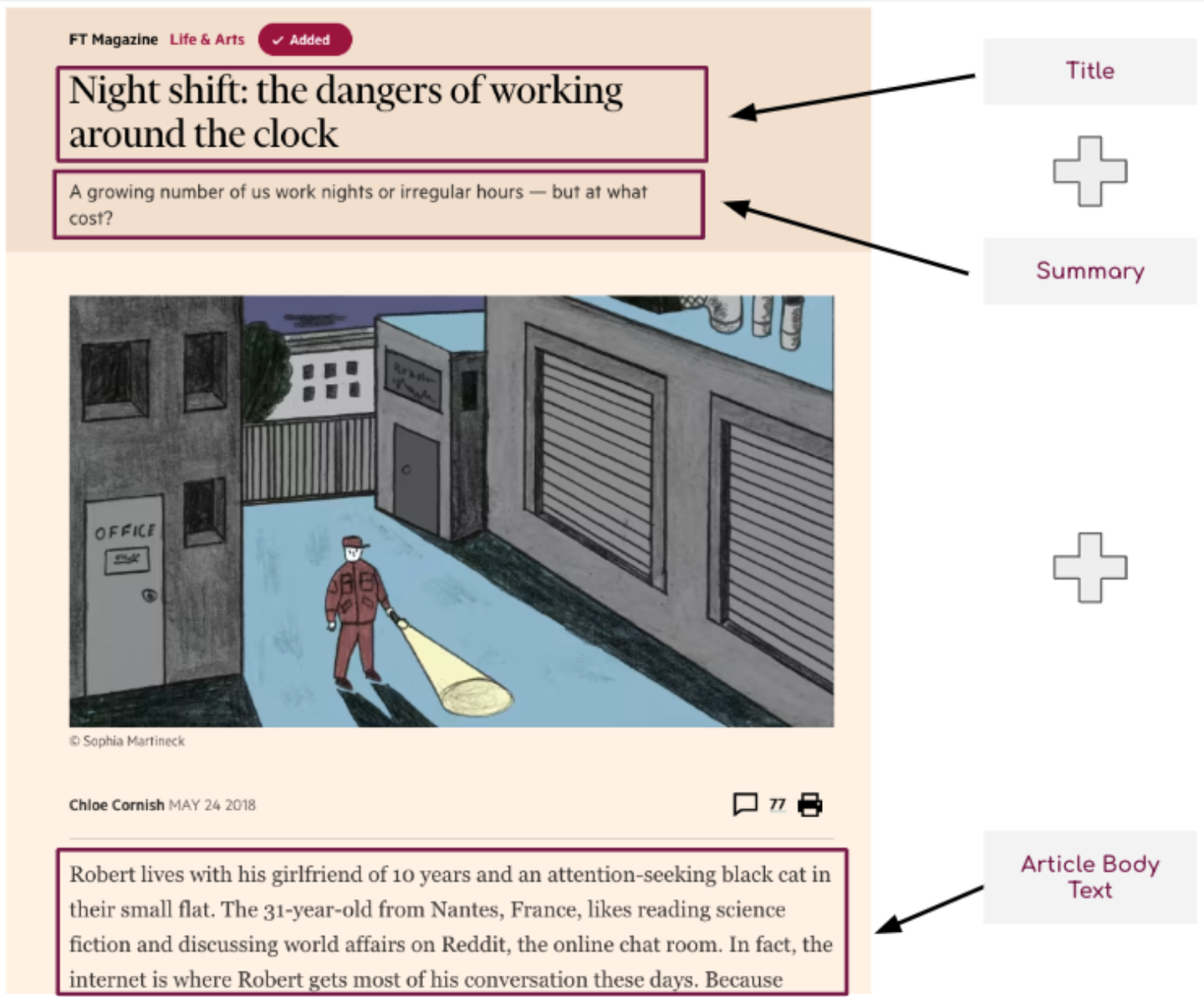
Following this, while most of the candidate models accept any length text inputs the team also needed to explore how to modify the dataset to overcome the text input limit for Sentence Transformers, as mentioned in section 1. In view of this, it was decided to concatenate the title, summary and article body text to form the text input for each model, as shown in Figure 1. This combination was chosen as the titles and summaries of FT articles are usually very descriptive and set the topic for the remaining article body text. Subsequently, grouping together the article elements proved very helpful as it ensured consistent testing of Sentence Transformers and reduced the chance of the model truncating text at an early stage in the article body text before a clear topic had been addressed.

3. Preparing the Candidate Models for Evaluation
The third stage of the project was to consolidate the research gathered per candidate model and decide on the final arrangement of parameters per candidate that would be tested.
TF-IDF
The scikit-learn implementation of TF-IDF was chosen and its parameters were examined and adjusted for our applications, for example, setting the a language for stopwords to “english”. In addition the values to set the maximum number of features and the length of input sequence to the TF-IDF matrix (N-gram parameter) were considered. Initial analysis indicated that our accuracy may improve were we to include bigrams; however this would cause the size of the matrix to become so vast that the memory of our modelling process would not be capable of handling this calculation. As a result, we chose to reduce the maximum features of the matrix and keep the bigram setting to ensure that exceeding the memory would not take place.
Doc2Vec
Our original model adopted the Doc2Vec implementation; however with this new iteration of the vectorisation model, there was an opportunity to test this Doc2Vec Gensim implementation using a range of different parameters e.g. changing the number of epochs or the output vector dimensions. However an important aspect to note about Gensim is that the same article vectorised twice with the same model would not produce the same vectors (see Gensim repo).
Sentence Transformers
In order to best represent the capabilities of Sentence Transformers, three specific models were opted-in for testing:


The choices were based on ensuring that our testing would include a model with a smaller vector dimensional output (384 dimensions), a larger vector dimensional output (768 dimensions) and a model which performed well in the SBert experimentation semantic search results.
Pooled Word Embeddings
Pooled word embeddings provide a fast and reasonable baseline considering they are able to accept the full length of text and so our team tested the average_word_embeddings_glove.840B.300d. This particular embedding carries the additional benefit that it is available directly from huggingface to be implemented via the scikit-learn fit-transform method similar to the sentence transformers. Nevertheless, it was uncertain at this stage how compatible a pooled word embedding would be for the FT applications of the new vectorisation model.
4. Evaluating the Candidate models
The three main areas that were targeted as potential applications of the vectors included testing similarity searching, classification, clustering and topic modelling. Overall the evaluation stage definitely formed a strong evidence base that creating vectors to be used across various applications could be possible without compromising model performance / quality of results.
Similarity
In order to evaluate whether the vectors created from our chosen candidates would be able to detect semantic similarity between similar articles and dissimilar articles, a cosine similarity distance test was introduced. This involved creating article triplets where there would be a pair of articles with a similar topic context and a third article with a dissimilar topic context.

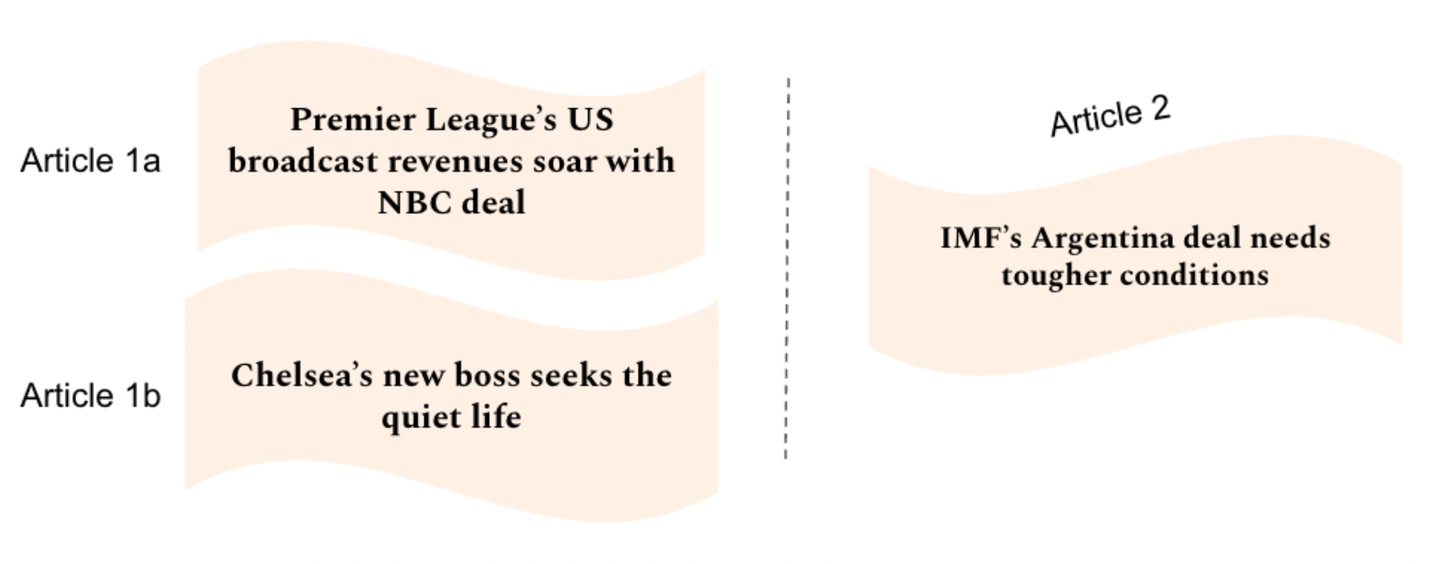
In Figure 2. above, the headlines of Article 1a and Article 1b have similar topics of football, whereas the headline of Article 2 indicates an article about a more unrelated financial topic. Subsequently the cosine similarity score was calculated between Articles 1a + 1b and Articles 1a+ 2 and tested by checking if the scores accurately reflected that the score between Articles 1a + 1b was greater than that for Articles 1a+ 2.
Table 1. shows the time taken for each method to vectorise all articles in the dataset on a CPU, followed by the % of correctly identified cases where cosine similarity scores between Articles 1a + 1b were higher than Articles 1a + 2.

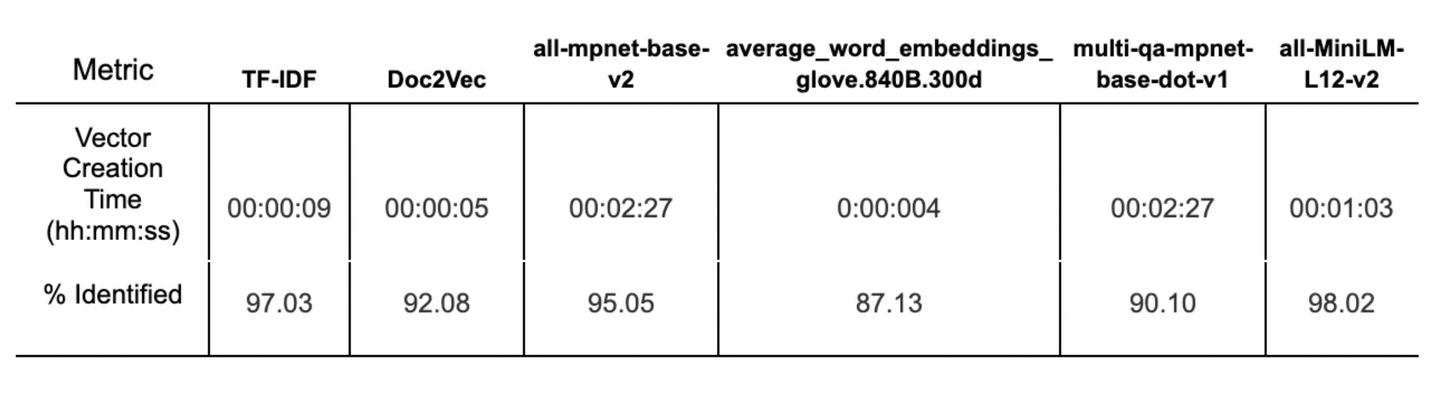
The results showed that the top two performers were TF-IDF and the Sentence Transformer model all-MiniLM-L12-v2, with the best % correct identification cosine similarity comparison. In addition to having a very high accuracy, TF-IDF had an extremely fast vector creation time. Among the Sentence Transformers, all-MiniLM-L12-v2 was more than twice faster on a CPU than all-mpnet-base-v2, while having a slightly better accuracy.
Classification
A common application within the FT for our stakeholders is text based classification, and so accordingly the next round of evaluation was to examine the ability of the vectors created to be used within a classification model. This particular test focused on a balanced multi-label classification dataset, where articles in the dataset could have up to three labels. Following this, the F1 scores of the classification tests are recorded in Table 2. below per vectorisation method.


The results of the classification tasks show that the sentence transformers as a group performed well, with all-mpnet-base-v2 and multi-qa-mpnet-base-dot-v1 taking the lead with the highest F1-Score. Nevertheless taking the top contenders: TF-IDF and all-MiniLM-L12-v2 they also performed equally well in the classification task.
Clustering
The final round of evaluation tasks focused on article clustering and topic modelling. In this phase the candidate embeddings were assessed on a set of clustering algorithms, outlined below:
- hierarchical clustering (using scikit-learn’s AgglomerativeClustering implementation with default settings)
- K-means (scikit-learn’s implementation with default settings)
- HDBSCAN (from python’s HDBSCAN library) and BERTopic, using HDBSCAN as a clustering algorithm.
The settings for each of the models was kept the same in order to facilitate easy identification of any differences in results attributed to the input embeddings. Subsequently the performance of the clustering models was evaluated through quantitative metrics, but most convincingly — qualitatively — through UMAP-based visualisations and topic coherence.
Clustering performance metrics
First, we compared the contenders on the same number of clusters and various clustering algorithms (hierarchical clustering and K-means), tracking silhouette scores and Calinski Harabasz Index Scores. The silhouette scores for K-means per input embedding, shown in Table 3 also reflect the other experimental results. The pooled GloVe word embeddings came on top, followed by various SentenceTransformers and relatively worse scores for Doc2Vec.


Next, we conducted experiments with HDBSCAN. We tracked the number of outliers and number of suggested clusters with the default parameters. We knew that FT content does not produce a high number of outlier articles and used it as an indicator for clusterability. Results are reported in Table 4 below. It became apparent that the Sentence Transformers; all-MiniLM-L12-v2 and all-mpnet-base-v2, allowed for clustering a much higher proportion of our training data without generating a high number of outliers. It was decided that the performance metrics alone would not provide enough complete information to make a selection of a candidate model.

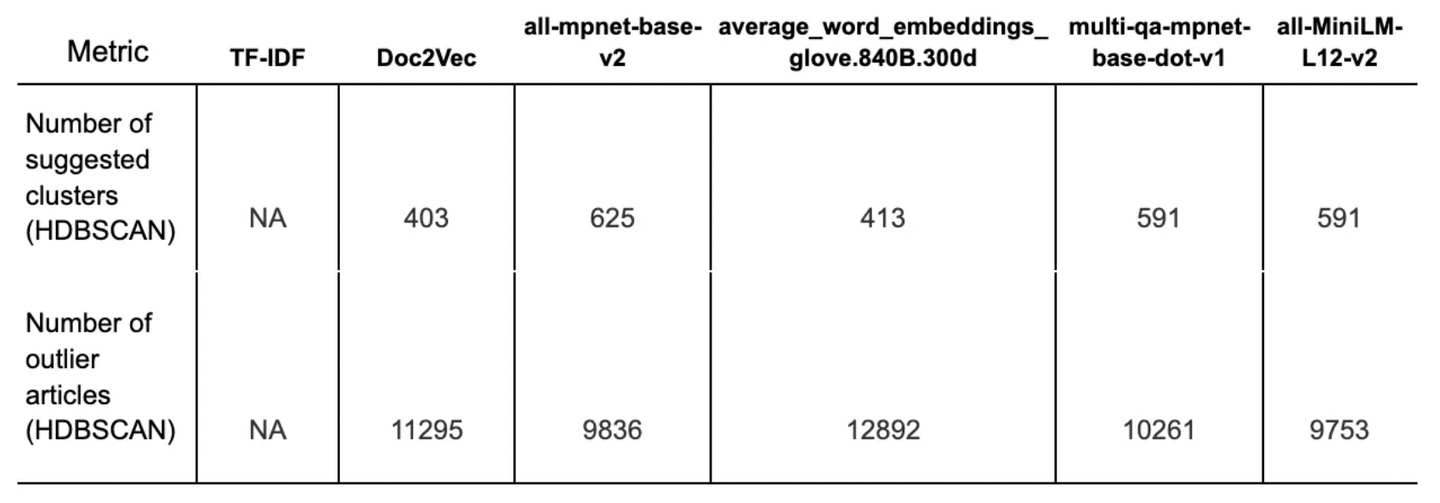
Qualitative assessment
Finally, the clusters were assessed qualitatively via BERTopic and bulk. A Streamlit dashboard was created for BERTopic topic modelling that facilitated the ability to quickly toggle between contenders and assess the quality of the topics produced. all-MiniLM-L12-v2 and all-mpnet-base-v2 showed the most coherent topics.
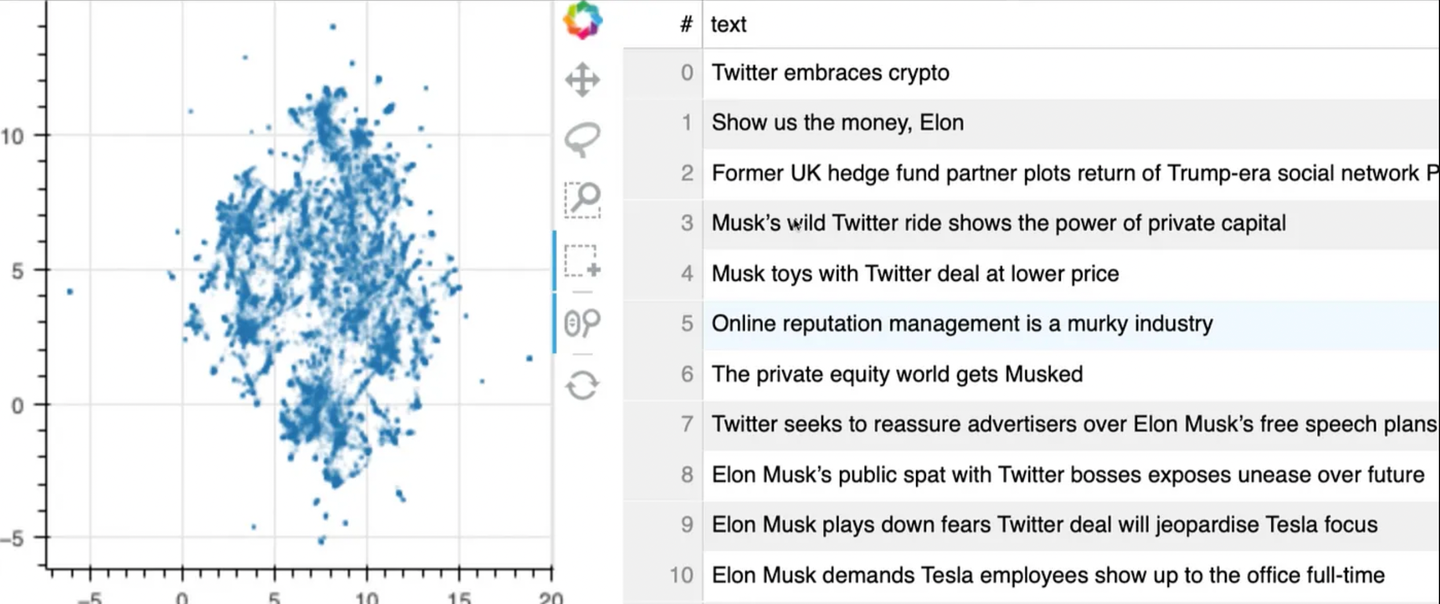
In addition, bulk UMAP projections were utilised to explore the embeddings. Below is a comparison between all-MiniLM-L12-v2 in Figure 3 and the Doc2Vec embeddings in Figure 4.
The all-MiniLM-L12-v2 embeddings were grouped much more naturally (both globally and locally), with similar articles forming “islands” of embeddings. In comparison, the Doc2Vec embeddings, while also being grouped nicely, formed a much less logical distance between individual articles and clusters.
The takeaway from the clustering experiment was that the Sentence Transformers allowed for much more natural clusters with very intuitive distances between articles.
MTEB
Around the same time of the evaluation phase in the project, a benchmarking piece, known as the Massive Text Embedding Benchmark or MTEB, was released on the huggingface blog. This benchmarking project detailed the performance of a range of text embedding models from the huggingface library (including two of our shortlist models: all-MiniLM-L12-v2, all-mpnet-base-v2) across different embedding tests. Each of the embedding test categories had a wide variety of datasets with short and long text inputs and different languages (see datasets MTEB page).
In particular as our applications of the chosen vectorisation model would involve classification and clustering, the results from these tasks found on the huggingface MTEB leaderboard page (shown in Figure 5.) were a useful insight in our decision making process.
The MTEB clustering task shows all-mpnet-base-v2 performed well, reaching the top 5 out of 47 models. Meanwhile all-MiniLM-L12-v2 placed 12 out of 47 models and was the top performing model with the smallest embedding dimension size in this task. In the classification both models also performed similarly to each other. Nevertheless it is worth noting the majority of models tested in MTEB generate vast embedding dimensions. Although these larger embedding dimensions demonstrate good clustering/classification capability, unfortunately this factor makes these models much harder to implement within a commercial context. This is due to computational requirements needed for testing and running the model as well as storing the outputs.

5. Choosing the winner
After reviewing all of the findings from our evaluation tasks, all of the results were saying the same thing (Figure 6). Conclusively we decided on the all-MiniLM-L12-v2 Sentence Transformer, for our final model!

